Posted 9 August 2018, 3:35 am EST
Hello,
we found an issue while exporting generated section report to PDF file.
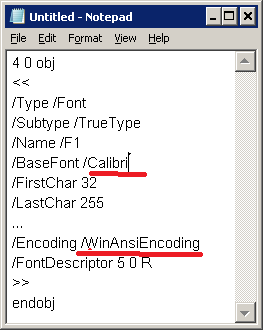
When we set Calibri font as NeverEmbedFonts, alpha character is exported using other font (MSUIGothic that is Embedded) but displayed in report preview using Calibri font. Additionally text in output PDF is cut off.
When we don’t set Calibri as NeverEmbedFonts alpha character is properly export to PDF.
Do you have any suggestions how to export alpha character properly while having Calibri added to NeverEmbedFonts (not Embedded)?
Why other font (MSUIGothic) is used for rendering alpha character with font that is Embedded?
We use AR v9.2.3032.0 and v11.2.10750.0.
This is urgent for us to resolve this issue. Thank you for your help.
Attachments in Zip File:
attachments.zip
HowToReproduce.PNG - how to reproduce
final.rpx - template to reproduce issue in sample AR designer.
1.rtf - rtf loaded to RTB control.
pdf_wrong_font.jpg - alpha character font properties (wrong font) when Calibri set as NeverEmbedFonts.
pdf_correct_font.jpg - alpha character font properties when Calibri not set as NeverEmbedFonts.
pdf_fonts_used.jpg - font used in our case in PDF file.
Calibri_Font_Installed.PNG - Calibri font installed in my PC