Posted 30 July 2018, 7:27 am EST
Hi Andreas,
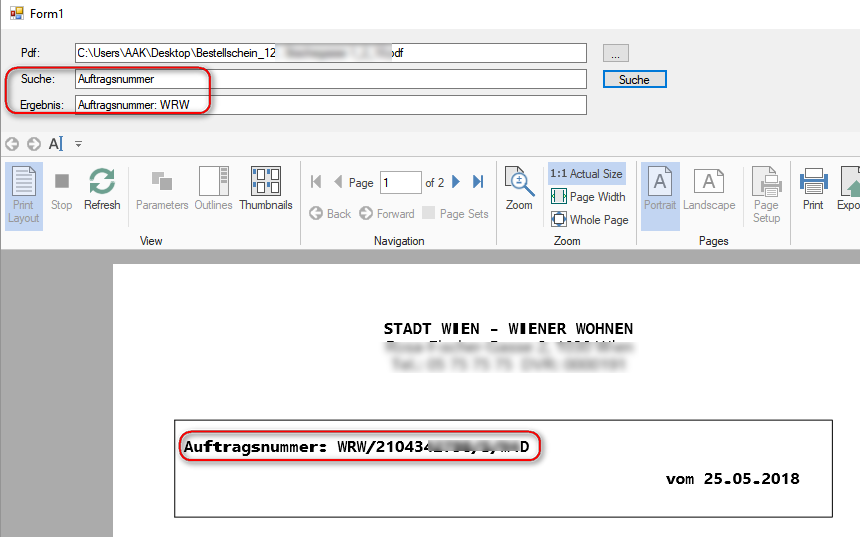
C1TextSearchManager has a property named NearText which as its name says, shows the text in neighborhood of the searched text. We can trim this NearText to remove all characters till the end of searched text and then store this in a global variable for any further usage.
string newText = "";
int index = -1;
if (_textSearchManager.FoundPositions.Count > 0)
{
index = _textSearchManager.FoundPositions[0].NearText.IndexOf(searchText, StringComparison.OrdinalIgnoreCase);
}
if (index != -1)
{
newText = _textSearchManager.FoundPositions[0].NearText.Remove(0, index + tbFindText.Text.Length);
}
else
{
// "from" not found
}
Hopefully this would help you meet your requirement.
Thanks,
Ruchir